
Generative AI is ushering in a new era of innovation, creativity and productivity. Just 18 months after it entered mainstream conversations, companies everywhere are investing in Generative AI to transform their organizations. Enterprises are realizing that their data is central to delivering a high-quality generative AI experience for their users. The urgent question among business leaders now is:
What’s the best and fastest way to do that?
With siloed data and AI platforms, it’s difficult for teams to accelerate their GenAI projects — whether they are using natural language to ask questions of their data or are building intelligent apps with their data. We believe that data intelligence platforms will result in radical democratization across organizations. This new category of data platforms uses GenAI to more easily secure and leverage data and lower the technical bar to create value from it. Among our own customers, there’s already a clear acceleration of AI adoption.
Three trends that are driving adoption across the board:
- Efficiency in deploying models: After years of being stuck experimenting with AI, companies are now deploying substantially more models into the real world than a year ago. On average, organizations became over 3 times more efficient at putting models into production. Natural language processing is the most-used and fastest-growing machine learning application.
- From RAGs to riches: In less than one year of integration, LangChain became one of the most widely used data and AI products. Companies are hyper focused on customizing LLMs with their private data using retrieval augmented generation (RAG). RAG requires vector databases, which grew 377% YoY. (Usage inclusive of both open source and closed LLMs.)
- Rise of SLMs: Many companies select smaller open-source models when considering trade-offs between cost, performance and latency. Only 4 weeks after launch, Meta Llama 3 accounts for 39% of all open-source model usage.
Companies invested in learning models has skyrocketed with more companies logging experimental models compared to a year ago, but even more are registering models. This indicates many companies that were focused on experimenting last year have now moved into production.
After years of intense focus on experimentation, organizations are now charging into production. ML is core to how companies innovate and differentiate. And as companies continue to build their confidence, we expect to see this trend continue in the coming years. The newer field of GenAI is still in the testing phase, but companies are starting to make traction.
ML efficiency has real value that can be measured in time, money and resources. While model development and experimentation are crucial, ultimately these models need to be deployed to real-world use cases to drive business value. Although Healthcare and Fintech have led the way in the past, the trend is shifting… Manufacturing, Automotive and retail consumer goods companies are becoming significantly more efficient at getting models into production, spending fewer resources on experimental models that never provide real-world value. Retail & Consumer Goods reached a ratio of one model in production for every four experimental models, one of the highest achieved efficiencies across industries. As outlined in the MIT Technical Review Insights report, Retail & Consumer Goods has long been an early-AI driver due to competitive pressure and consumer expectations.
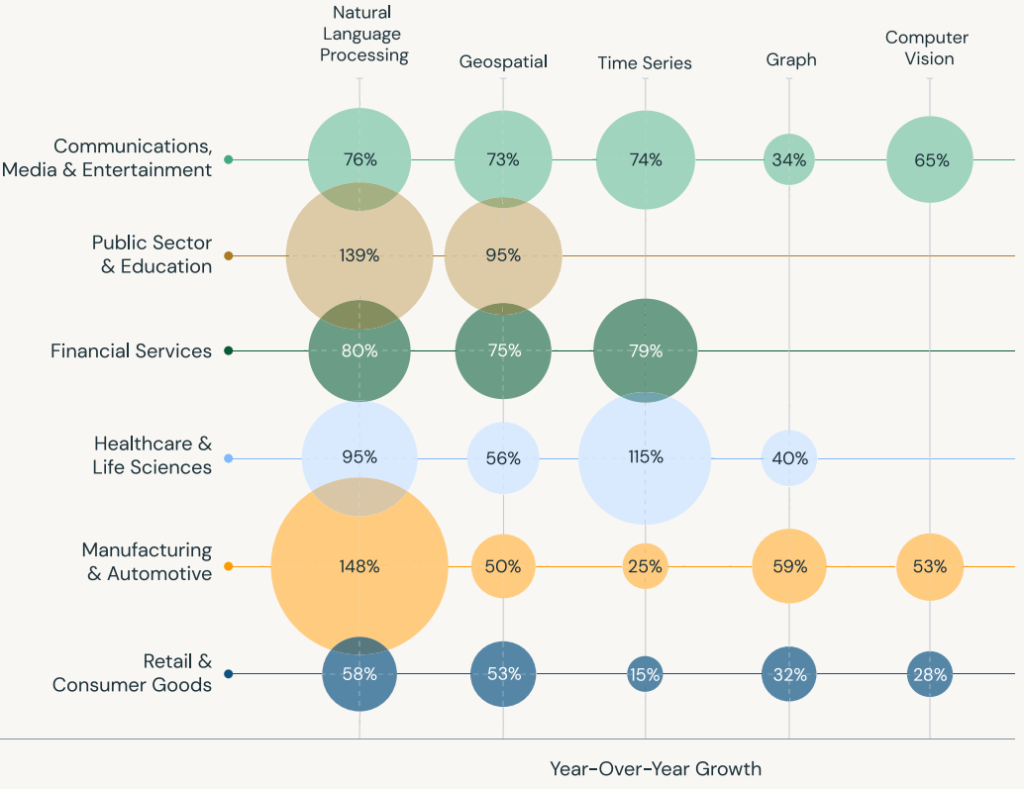
NLP Explosion Unstructured data is ubiquitous across industries and regions, making natural language processing (NLP) techniques essential to derive meaning. GenAI is a key use case of NLP. It remains the most widely used DS/ML application, isn’t slowing down. With the rise of AI-driven applications, there’s a growing demand for NLP solutions across industries. While NLP dominates the use of Python libraries, it also has the highest growth of all applications YoY.
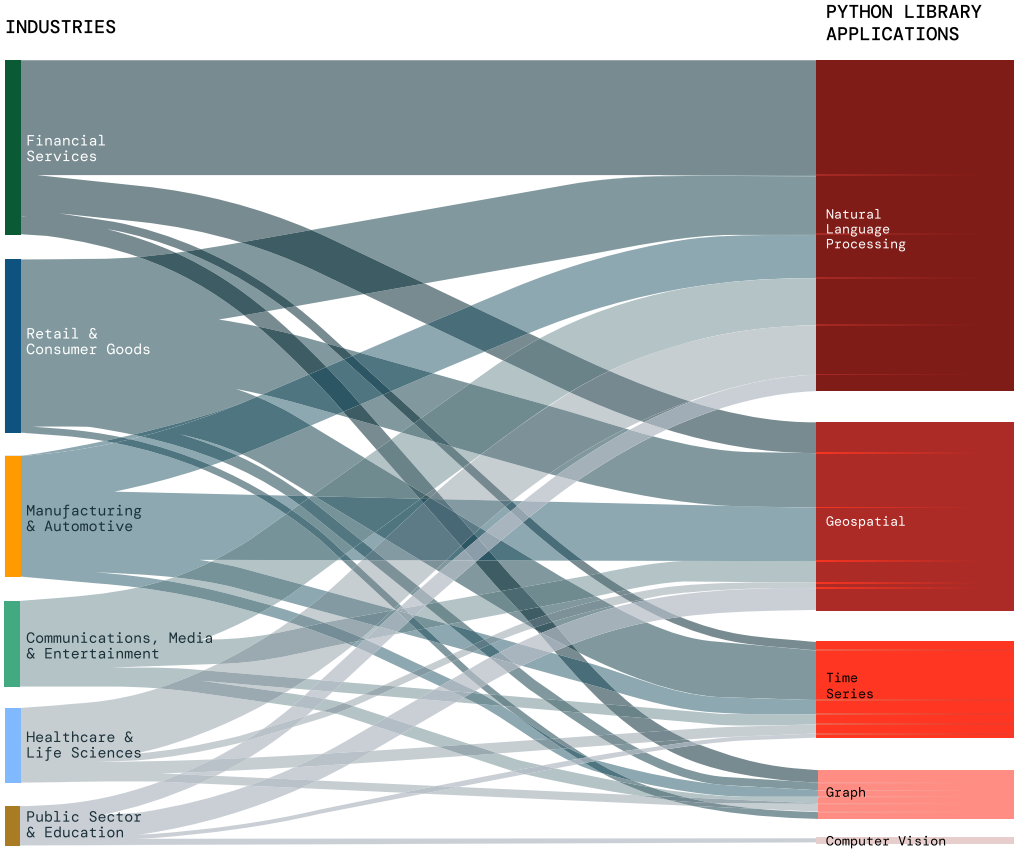
ALL INDUSTRIES INVEST HEAVILY IN NLPManufacturing & Automotive had the largest gains in use of NLP — which helps the industry do everything from analyzing feedback from customers to monitoring quality control to powering chatbots — enables companies to improve operational efficiency.
Data leaders are always searching for the best tools to deliver their AI strategies. Top 10 Data and AI Products showcase the most widely adopted integrations. Categories include DS/ML, data governance and security, orchestration, data integration and data source products. Among our top products, 9 out of 10 are open source. Organizations are choosing more flexibility while avoiding proprietary walls and restrictions. Some exceptional leaders at the moment:
- Plotly Dash is a low-code platform that enables data scientists to easily build, scale and deploy data applications. Products like Dash help companies deliver applications faster and more easily to keep up with dynamic business needs. For more than 2 years, Dash has held its position as No. 1, which speaks to the growing pressure on data scientists to develop production-grade data and AI applications.
- Hugging Face Transformers ranks as the second most popular product used among our customers, up from No. 4 a year ago. Many companies use the open source platform’s pretrained transformer models together with their enterprise data to build and fine-tune foundation models. This supports a growing trend we’re seeing with RAG applications.
- LangChain — an open source toolchain for working with and building proprietary LLMs — jumped into the top ranks last spring and rose to No. 4 in less than one year of integration. When companies build their own modern LLM applications and work with specialized transformer-related Python libraries to train the models, LangChain enables them to develop prompt interfaces or integrations to other systems.
- High Quality Datasets: Companies are also investing in products to build high quality datasets. Current front runners are dbt (data transformation), Fivetran (automation of data pipelines) and Great Expectations (data quality) all have steady growth.
The case for Vector databases & the goldrush to customize LLMs – LLMs support a variety of business use cases with their language understanding and generation capabilities. However, especially in enterprise settings, LLMs alone have limitations. They can be unreliable information sources and are prone to providing erroneous information, called hallucinations. At the root, stand-alone LLMs aren’t tailored to the domain knowledge and needs of a specific organization. More and more companies are turning to RAG instead of relying on stand-alone LLMs. RAG enables organizations to use their own proprietary data to better customize LLMs and deliver high-quality GenAI apps. By providing LLMs with additional relevant information, the models can give more accurate answers and are less likely to hallucinate.
WHAT IS RAG?
Retrieval augmented generation (RAG) is a GenAI application pattern that finds data and documents relevant to a question or task and provides them as context for the LLM to give more accurate responses.
HOW DO VECTOR DATABASES AND RAG WORK TOGETHER?
Vector databases generate representations of predominantly unstructured data. This is useful for information retrieval in RAG applications to find documents or records based on their similarity to keywords in a query. RAG applications have a lot of advantages over off the shelf. RAG has quickly emerged as a popular way to incorporate proprietary, real-time data into LLMs without the costs and time requirements of fine-tuning or pretraining a model. The exponential growth of vector databases suggests that companies are building more RAG applications in order to integrate their enterprise data with their LLMs.
COMPANIES ARE BECOMING MORE SOPHISTICATED IN BUILDING LLMs
Last year, customers were jumping into LLMs with off-the-shelf models. We still see growth in the number of customers using SaaS LLMs. But companies are beginning to take more control over their LLMs and build tools specific to their needs. The continuing growth of vector databases, LLM tools and transformer-related libraries shows that many data teams are choosing to build vs. buy. Companies increasingly invest in LLM tools, such as LangChain, to work with and build proprietary LLMs. Transformer related libraries like Hugging Face are used to train LLMs, and still claim the highest adoption by number of customers. Use of these libraries grew significantly YoY. Together, these trend lines indicate a more sophisticated adoption of open source LLMs.
Real-time ML systems are revolutionizing how businesses operate by providing the ability to make immediate predictions or actions based on incoming data. But they need a fast and scalable serving infrastructure that requires expert knowledge to build and maintain. Serverless model serving automatically scales up or down to meet demand changes, reducing cost as companies only pay for their consumption. Companies can build real-time ML applications ranging from personalized recommendations to fraud detection. Model serving also helps support LLM applications for user interactions. We have seen steady growth in the adoption of serverless data warehousing and monitoring, which also scales with demand.
Conclusion
Data science and AI are propelling companies toward greater efficiency, and GenAI is opening up a new landscape of possibilities. With data intelligence platforms, there is one cohesive, governed place for the entire organization to use data and AI. Companies across all industries are embracing these tools, and early adopters may come from industries you may not expect. Organizations have realized measurable gains in putting ML models into production. Companies are increasingly adopting and using NLP to unlock insights from data. They are using vector databases and RAG applications to integrate their own enterprise data into their LLMs. Open source tools are the future, as they continue to rank high among our most popular products. Companies are strategizing with unified data and AI governance.
The takeaway: The winners in every industry will be those who most effectively use data and AI.